
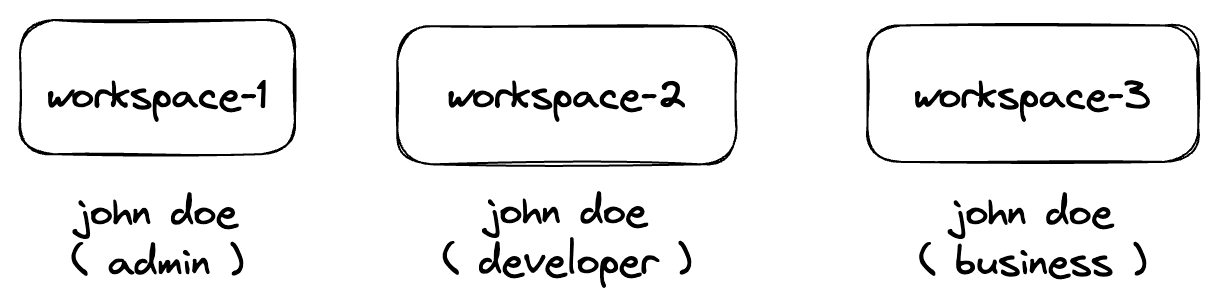
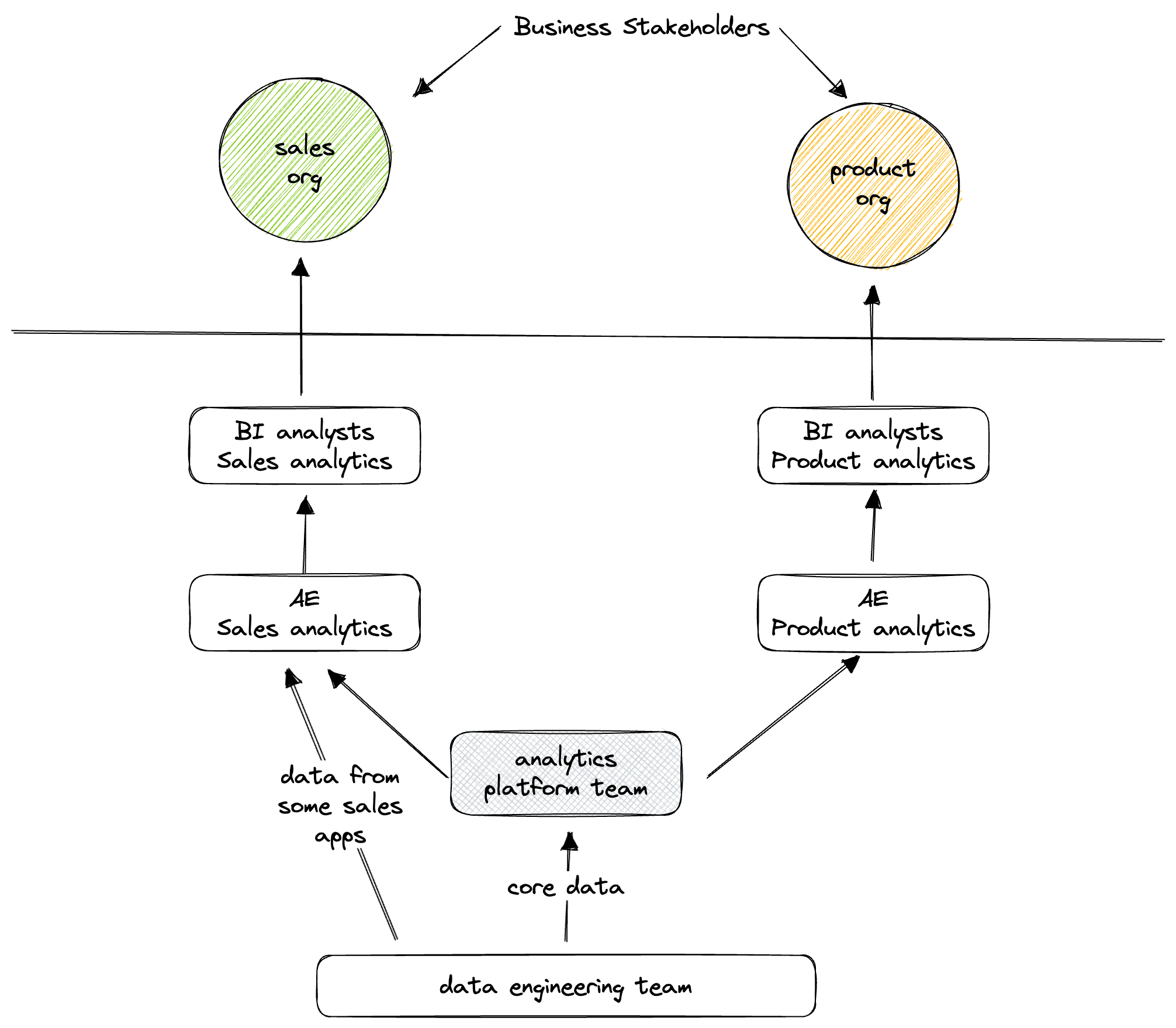
Sample team structure aligned to business units
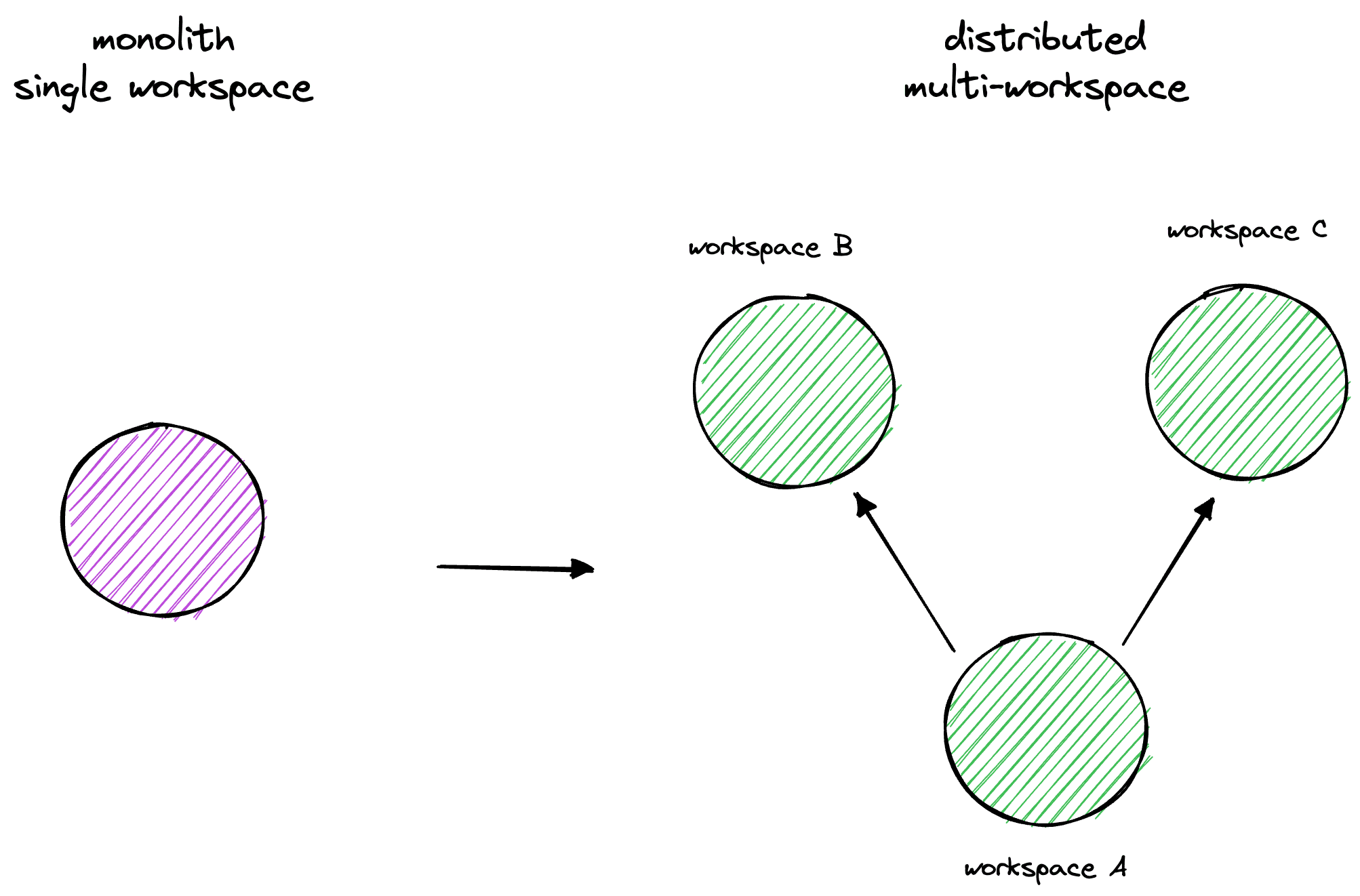
Monolith vs distributed multi-workspace
Creating a workspace

Adding a new workspace

Data mesh in an enterprise or mid-market business
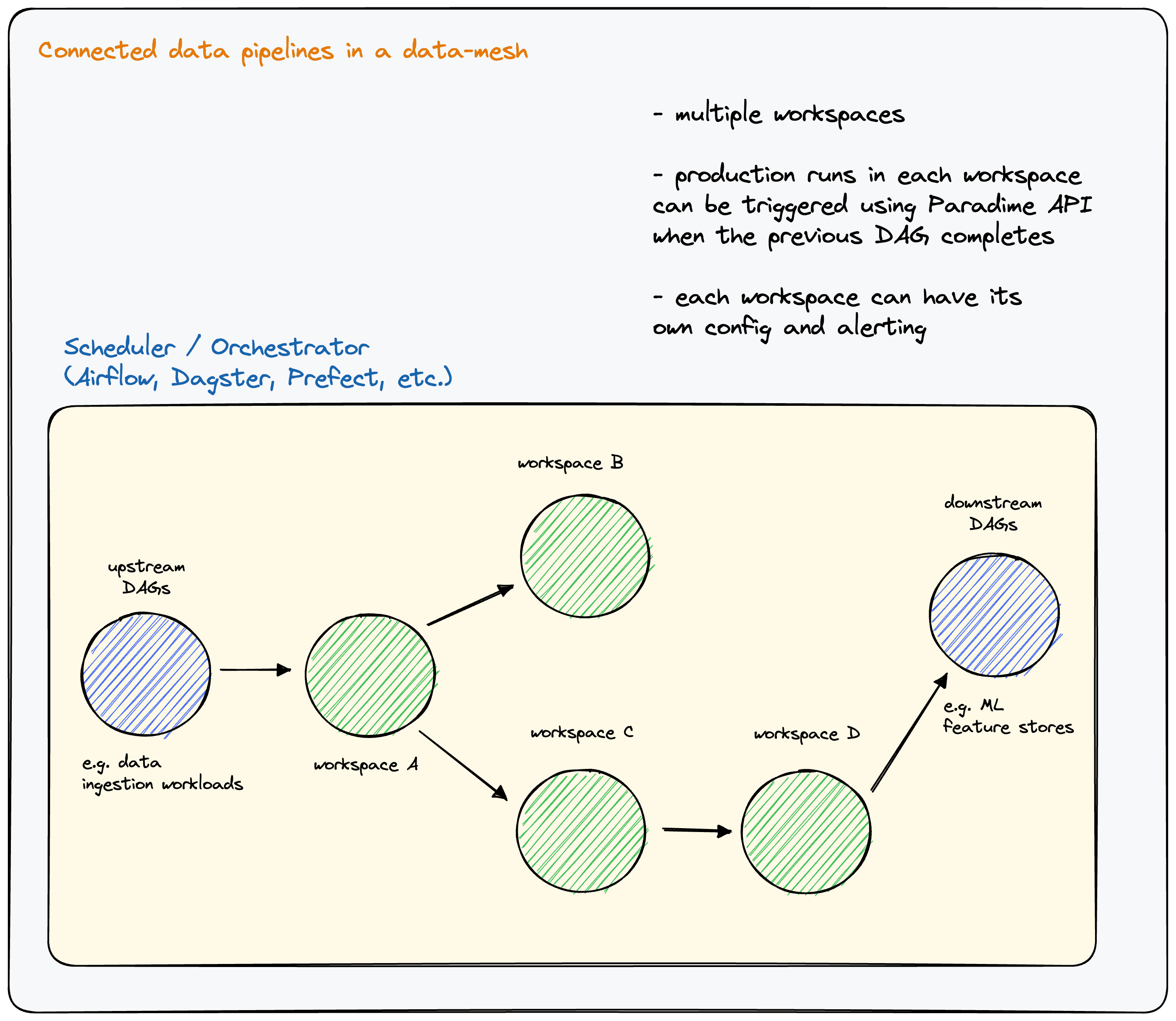
Connected data pipeline across workspaces
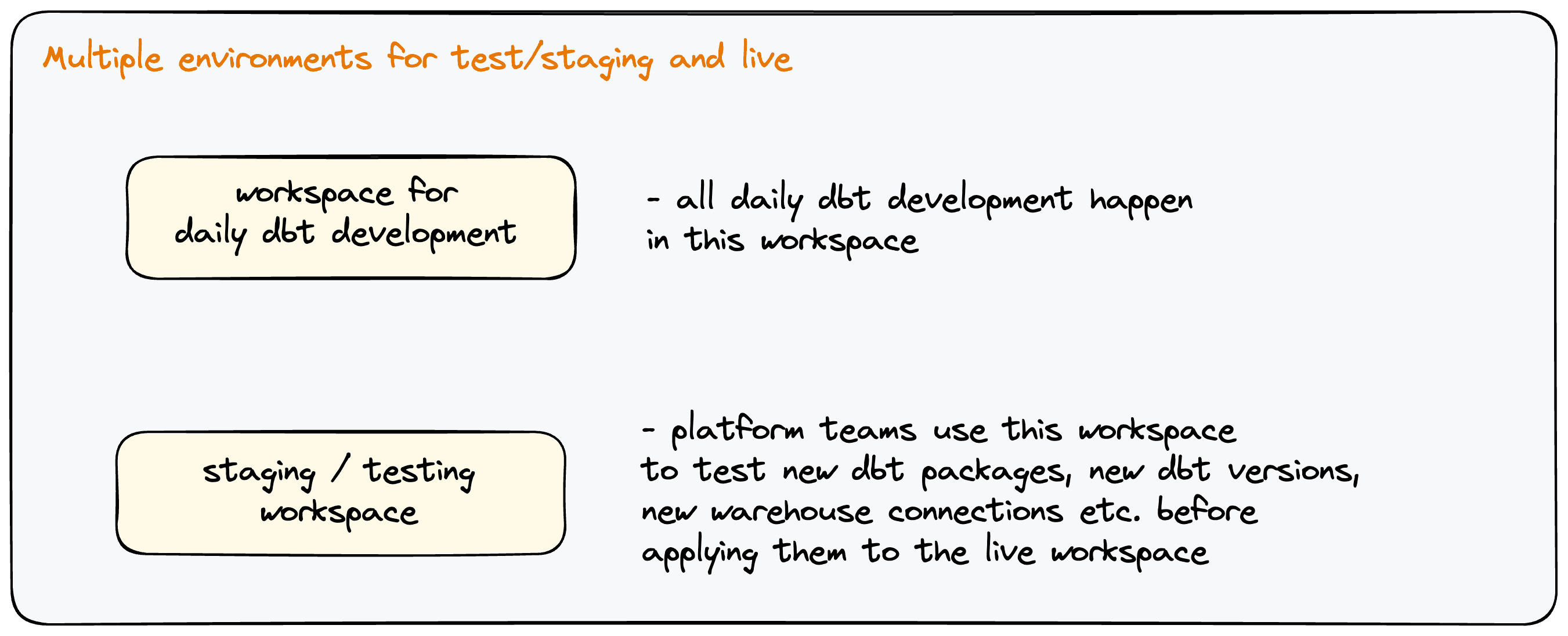
Multiple environments for production and testing / staging
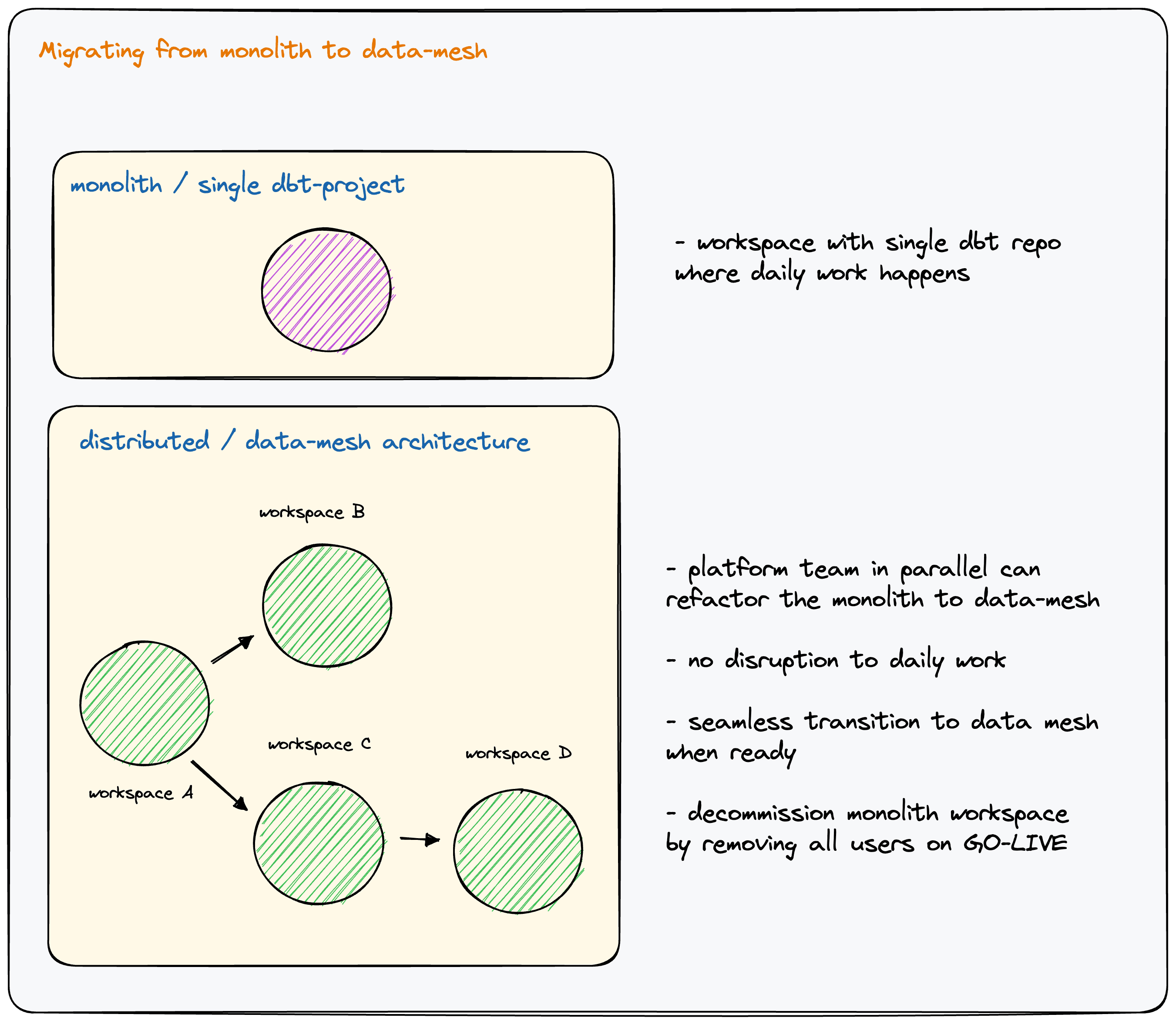
Migrating from a monolith to a data mesh
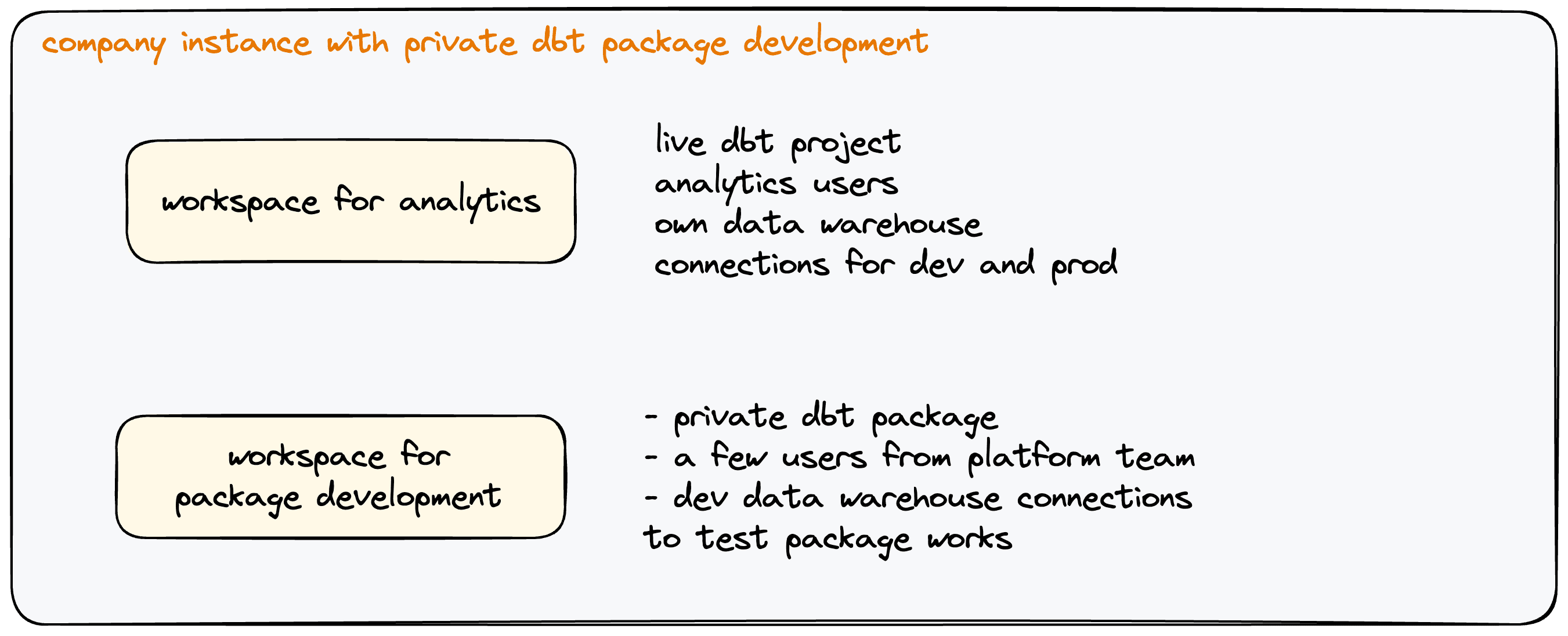
Developing internal dbt™ packages
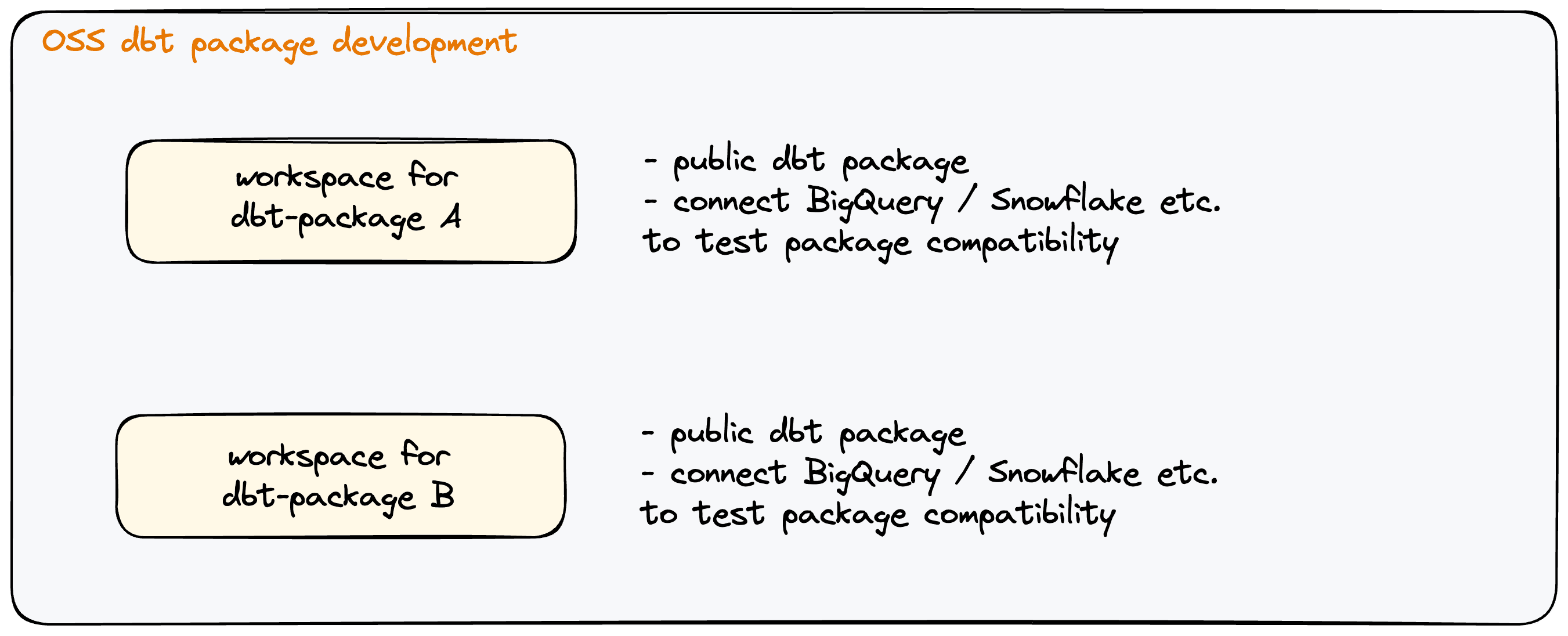
Developing open source package